AI竞技场,归根到底只是一门生意
文 | 锦缎
“XX发布最强开源大模型,多项基准测试全面超越XX等闭源模型!”
“万亿参数开源模型XX强势登顶全球开源模型榜首!”
“国产之光!XX模型在中文评测榜单拿下第一!”
随着AI时代的到来,各位的朋友圈、微博等社交平台是不是也常常被诸如此类的新闻刷屏了?
今天这个模型拿到了冠军,明天那个模型变成了王者。评论区里有的人热血沸腾,有的人一头雾水。
一个又一个的现实问题摆在眼前:
这些模型所谓的“登顶”比的是什么?谁给它们评分,而评分的依据又是什么?为什么每个平台的榜单座次都不一样,到底谁更权威?
如果各位也产生了类似的困惑,说明各位已经开始从“看热闹”转向“看门道”。
本文之中,我们便来拆解一下不同类型“AI竞技场”——也就是大语言模型排行榜——的“游戏规则”。
01 类型一:客观基准测试(Benchmark),给AI准备的“高考”
人类社会中,高考分数是决定学生大学档次的最主要评判标准。
同样地,在AI领域,也有很多高度标准化的测试题,用来尽可能客观地衡量AI模型在特定能力上的表现。
因此,在这个大模型产品频繁推陈出新的时代,各家厂商推出新模型后,第一件事就是拿到“高考”考场上跑个分,是骡子是马,拉出来遛遛。
Artificial Analysis平台提出了一项名为“Artificial Analysis Intelligence Index(AAII)”的综合性评测基准,汇总了7个极为困难且专注于前沿能力的单项评测结果。
类似于股票价格指数,AAII能够给出衡量AI智能水平的综合分数,尤其专注于需要深度推理、专业知识和复杂问题解决能力的任务。
这7项评测覆盖了被普遍视作衡量高级智能核心的三个领域:知识推理、数学和编程。
(1)知识与推理领域
MMLU-Pro:
全称Massive Multitask Language Understanding - Professional Level
MMLU的加强版。MMLU涵盖57个学科的知识问答测试,而MMLU-Pro在此基础上,通过更复杂的提问方式和推理要求,进一步增加难度以测试模型在专业领域的知识广度和深度推理能力。
GPQA Diamond:
全称Graduate - Level Google - Proof Q&A - Diamond Set
此测试机包含生物学、物理学和化学领域的专业问题。与其名称对应,其设计初衷很直白:即使是相关领域的研究生,在允许使用Google搜索的情况下也很难在短时间内找到答案。而Diamond正是其中难度最高的一个子集,需要AI具备较强的推理能力和问题分解能力,而非简单的信息检索。
Humanity’s Last Exam:
由Scale AI和Center for AI Safety(CAIS)联合发布的一项难度极高的基准测试,涵盖科学、技术、工程、数学甚至是人文艺术等多个领域。题目大多为开放式,不仅需要AI进行多个步骤的复杂推理,还需要AI发挥一定的创造性。这项测试能够有效评估AI是否具备跨学科的综合问题解决能力。
(2)编程领域
LiveCodeBench:
这是一项贴近现实的编程能力测试。与传统的编程测试只关注代码的正确性不同,AI会被置于一个“实时”的编程环境中,并根据问题描述和一组公开的测试用例编写代码,而代码将会使用一组更复杂的隐藏测试用例运行并评分。这项测试主要考验AI编程是否具备较高的鲁棒性以及处理边界情况的能力。
SciCode:
这一项编程测试则更偏向于学术性,专注于科学计算和编程。AI需要理解复杂的科学问题并用代码实现相应的算法或模拟。除了考验编程技巧,还需要AI对科学原理具备一定深度的理解。
(3)数学领域
AIME:
全称American Invitational Mathematics Examination
美国高中生数学竞赛体系中的一环,难度介于AMC(美国数学竞赛)和USAMO(美国数学奥林匹克)之间。其题目具备较高的挑战性,需要AI具备创造性的解题思路和数学功底,能够衡量AI在高级数学领域中的推理能力。
MATH-500:
从大型数学问题数据集“MATH”中随机抽取500道题构成的测试,覆盖从初中到高中竞赛水平的各类数学题目,涵盖代数、几何和数论等领域。题目以LaTeX格式给出,模型不仅要给出答案,还需要有详细的解题步骤,是评估AI形式化数学推理和解题能力的重要标准。
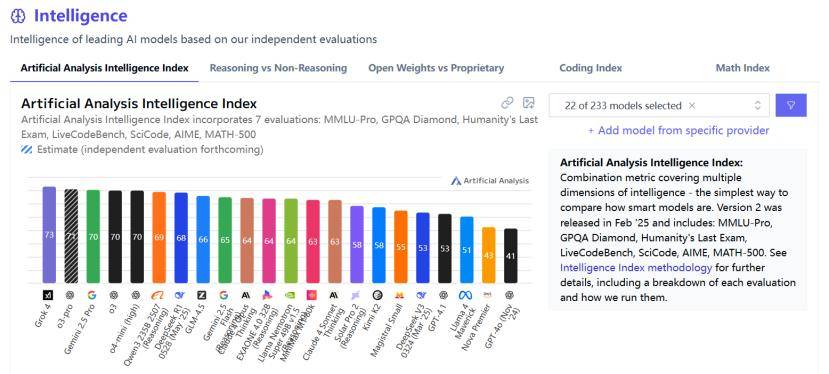
图:Artificial Analysis的AI模型智能排行榜
不过,由于模型的用处不同,各大平台并不会采用相同的测评标准。
例如,司南(OpenCompass)的大语言模型榜单根据其自有的闭源评测数据集(CompassBench)进行评测,我们无法得知具体测试规则,但该团队面向社区提供了公开的验证集,每隔3个月更新评测题目。
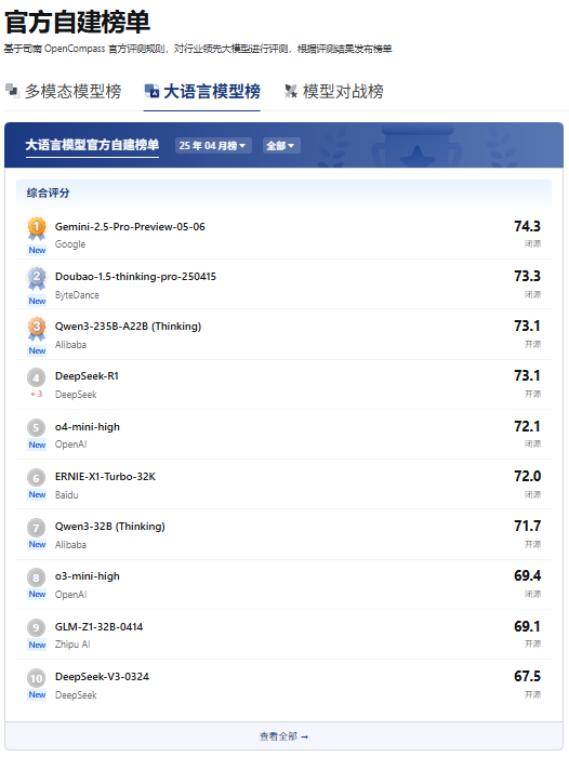
图:OpenCompass大语言模型榜
与此同时,该网站也选取了一些合作伙伴的评测集,针对AI模型的主流应用领域进行评测并发布了测试榜单:

而HuggingFace也有类似的开源大语言模型榜单,测评标准中包含了前面提过的MATH、GPQA和MMLU-Pro:
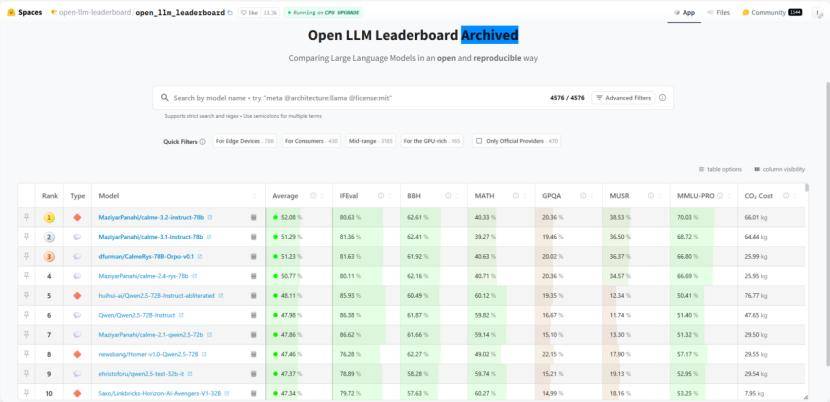
图:HuggingFace上的开源大语言模型排行榜
在这个榜单中,还增加了一些测评标准,并附有解释:
IFEval:
全称Instruction-Following Evaluation
用于测评大语言模型遵循指令的能力,其重点在于格式化。这项测评不仅需要模型给出正确的回答,还注重于模型能否严格按照用户给出的特定格式来输出答案。
BBH:
全称Big Bench Hard
从Big Bench基准测试中筛选出的一部分较为困难的任务,构成了专门为大语言模型设计的高难度问题集合。作为一张“综合试卷”,它包含多种类型的难题,如语言理解、数学推理、常识和世界知识等方面。不过,这份试卷上只有选择题,评分标准为准确率。
MuSR:
全称Multistep Soft Reasoning
用于测试AI模型在长篇文本中进行复杂、多步骤推理能力的评测集。其测试过程类似于人类的“阅读理解”,在阅读文章后,需要将散落在不同地方的线索和信息点串联起来才能得到最终结论,即“多步骤”和“软推理”。此测评同样采用选择题的形式,以准确率为评分标准。
CO2 Cost:
这是最有趣的一项指标,因为大部分LLM榜单上都不会标注二氧化碳排放量。它只代表了模型的环保性和能源效率,而无法反映其聪明程度和性能。
同样地,在HuggingFace上搜索LLM Leaderboard,也可以看到有多个领域的排行榜。
图:HuggingFace上的其他大语言模型排行榜
可以看到,把客观基准测试作为AI的“高考”,其优点很明确:客观、高效、可复现。
同时,可以快速衡量模型在某一领域或某一方面的“硬实力”。
但伴随“高考”而来的,则是应试教育固有的弊端。
模型可能在测试中受到数据污染的影响,导致分数虚高,但实际应用中却一问三不知。
毕竟,在我们先前的大模型测评中,简单的财务指标计算也可能出错。
同时,客观基准测试很难衡量模型的“软实力”。
文本上的创造力、答案的情商和幽默感、语言的优美程度,这些难以量化、平时不会特意拿出来说的衡量指标,却决定着我们使用模型的体验。
因此,当一个模型大规模宣传自己在某个基准测试上“登顶”时,它就成为了“单科状元”,这已经是很了不起的成就,但离“全能学霸”还有很远距离。
02 类型二:人类偏好竞技场(Arena),匿名才艺大比拼
前面已经说过,客观基准测试更注重于模型的“硬实力”,但它无法回答一个最实际的问题:
一个模型,到底用起来“爽不爽”?
一个模型可能在MMLU测试中知晓天文地理,但面对简单的文字编辑任务却束手无策;
一个模型可能在MATH测试中秒解代数几何,却无法理解用户话语中的一丝幽默和讽刺。
面对上述困境,来自加州大学伯克利分校等高校的研究人员组成的LMSys.org团队提出了一个想法:
“既然模型最终为人而服务,那为什么不直接让人来评判呢?”
这一次,评判标准不再是试卷和题集,评分标准交到了用户手中。
LMSys Chatbot Arena,一个通过“盲测对战”来对大语言模型进行排名的大型众包平台。
对战时,两个模型同时登场,并对同一个问题进行解答,由用户决定谁输谁赢。
用户在投票前无法得知两个“选手”的“真实身份”,有效消除了刻板偏见。
对于一般用户来说,LMArena的使用方法非常简单:
登录https://lmarena.ai/后,首先由用户进行提问,系统会随机挑选两个不同的大语言模型,并将问题同时发送给它们。
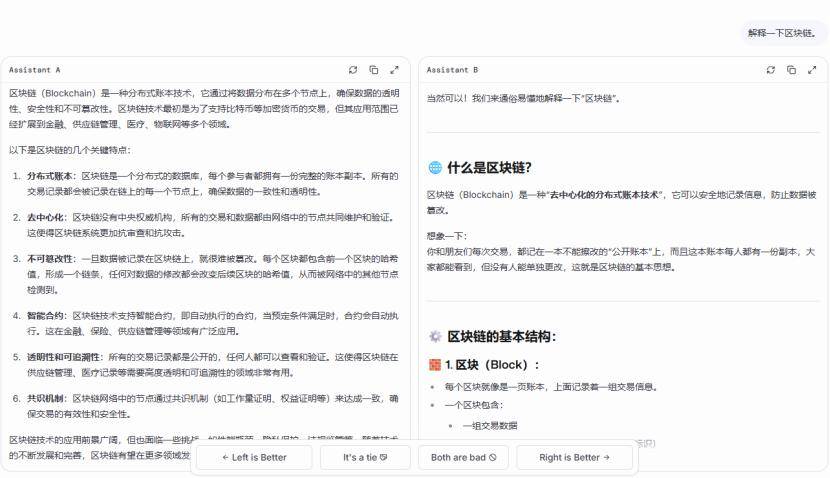
匿名标注为Assistant A和Assistant B两个模型生成的答案会并排显示,而用户需要根据自己的判断,投票选择最合适的回答。
而在投票后,系统才会告知用户Assistant A和Assistant B分别是哪个模型,而这次投票也会加入到全球用户的投票数据中。
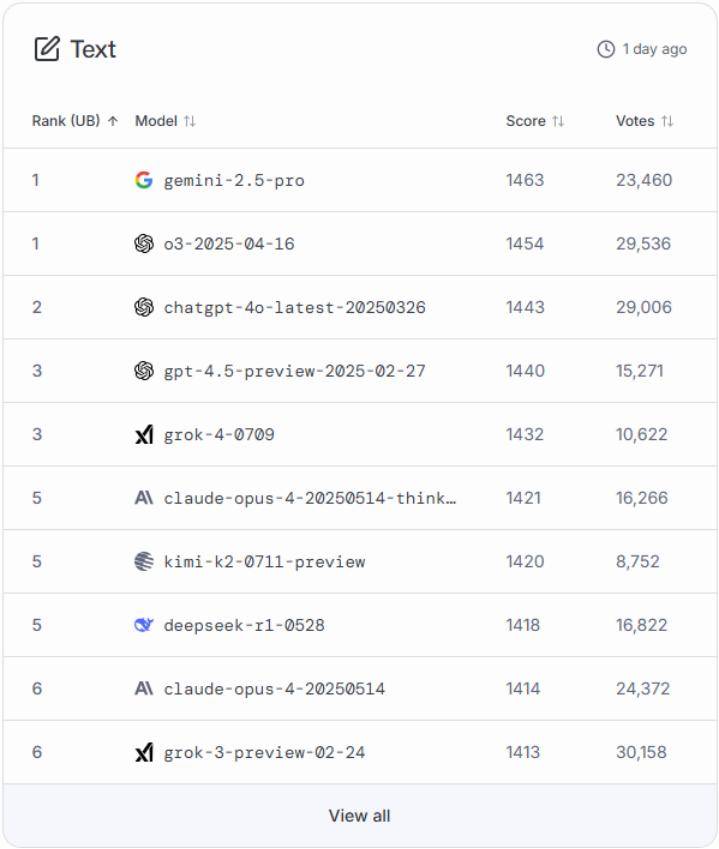
图:LMArena文本能力排行榜
LMArena中设计了七个分类的排行榜,分别是Text(文本/语言能力)、WebDev(Web开发)、Vision(视觉/图像理解)、Text-to-Image(文生图)、Image Edit(图像编辑)、Search(搜索/联网能力)和Copilot(智能助力/代理能力)。
每个榜单都是由用户的投票产生的,而LMArena采用的核心创新机制就是Elo评级系统。
这套系统最初用于国际象棋等双人对战游戏,可用于衡量选手的相对实力。
而在大模型排行榜中,每个模型都会有一个初始分数,即Elo分。
当模型A在一场对决中战胜模型B时,模型A就可以从模型B那赢得一些分数。
而赢得多少分数,取决于对手有多少实力。如果击败了分数远高于自己的模型,则会获得大量分数;如果只是击败了分数远低于自己的模型,则只能获得少量分数。
因此,一旦输给弱者,则会丢掉大量分数。
这个系统很适合处理大量的“1v1”成对比较数据,能够判断相对强弱而非绝对强弱,并能够使排行榜动态更新,更具备可信度。
尽管有相关研究人员指出LMArena的排行榜存在私测特权、采样不公等问题,但它仍是目前衡量大语言模型综合实力较为权威的排行榜之一。
在AI新闻满天飞的环境下,它的优势在于消除用户先入为主的偏见。
同时,我们前面提到的创造力、幽默感、语气和写作风格等难以量化的指标将在投票中得以体现,有助于衡量主观质量。
但是,简单的流程和直观的“二选一”也为类似的竞技场平台带来了不少局限性:
一是聚焦于单轮对话:其评测主要采取“一问一答”的方式,而对于需要多轮对话的任务则难以充分进行评估;
二是存在投票者偏差:这是统计中难以避免的现象,投票的用户群体可能更偏向于技术爱好者,其问题类型和评判标准必然无法覆盖普通用户;
三是主观性过强:用户对于“好”和“坏”的评判过于主观,而Elo分数则只是体现主观偏好的平均结果;
四是缺失事实核查性:用户在对两个模型进行评判时,注意力往往放在答案的表述上,而忽视了回答内容的真实性。
03 我们到底该看哪个排行榜?
AI江湖的“武林大会”远不止我们提到的这些排行榜。随着AI领域规模的不断扩大,评测的战场本身也变得越来越复杂和多元化。
很多学术机构或大型AI公司会发布自家的评测报告或自建榜单,体现出技术自信,但作为用户,则需要“打个问号”。
就像足球比赛有主客场之分,机构也可以巧妙地设计评测的维度和题目,使其恰好能放大某些模型的优势,同时规避其弱点。
另一个更加宏大的趋势是,大模型的评测榜单正在从“大一统”走向“精细化”。
据不完全统计,迄今为止,全球已发布大模型总数达到3755个。
“千模大战”的时代,一份冗长的通用榜单,显然无法满足所有人的需求。
因此,评测的趋势也不可避免地走向细分化和垂直化。
那么回到最初的核心问题:到底谁更权威?
观点很明确:没有任何一个单一的排行榜是绝对权威的。
排行榜终究是参考,甚至不客气的说,“AI竞技场”归根到底只是一门生意。对于高频刷榜的模型,我们务必要警惕——不是估值需求驱动,便是PR导向驱动。是骡子是马,终究不是一个竞技场能盖棺定论的。
但对于普通用户来说,评判一个模型的最终标准是唯一的:它是否真正对你有用。
评价和选择模型,要先看应用场景。
如果你是程序员,就去试试AI编写代码、检查和修复Bug的能力;
如果你是大学生,就让AI去做文献综述,解释学术名词和概念;
如果你是营销人,就看看AI能否写出精彩的文案、构思和创意。
别让“登顶”的喧嚣干扰了你的判断。
大模型是工具,不是神。看懂排行榜,是为了更好地选择工具。
与其迷信排行榜,真如把实际问题交给它试一试,哪个模型能最高效优质地解决问题,它就是你的“私人冠军”。